
近年、会議の録音データやユーザーの音声入力など、様々な場面で音声データが増えています。これらのデータを文字に起こすニーズが高まっている一方で、手作業での文字起こしは非常に時間がかかる作業です。
そこで、この記事ではノーコードツールのMake.comと音声認識APIのAssemblyAIを組み合わせた、自動文字起こしの方法をご紹介します。プログラミング不要で、簡単に音声ファイルを文字起こしできます。
Make.comとは?
Make.comは、様々なWebサービスやアプリを連携させて、自動化ワークフローを作成できるノーコードツールです。例えば、「Gmailに特定のメールが届いたらSlackに通知する」「Googleフォームの回答をスプレッドシートに自動で記録する」といった自動化が、プログラミングなしで実現できます。

Make.comは強力なノーコード自動化プラットフォームであり、異なるWebサービスやアプリケーション間のデータの移動とタスクの自動化を実現します。特にプログラミング知識がない個人や企業にとって、複雑なコーディングなしで効率的なワークフローを構築することができます。
主な特徴と機能
- 視覚的なワークフロー作成: ドラッグアンドドロップのインタフェースを通じて、アプリケーション間のアクションを簡単にリンクできます。
- 幅広いアプリケーションとの連携: 1,000を超えるアプリケーションとの連携が可能で、Gmail、Slack、Google Drive、Dropboxなどの一般的なサービスから、CRMやマーケティングツールまで幅広く対応しています。
- 条件分岐とカスタムロジック: 複数の条件に基づいて異なるアクションをトリガーすることが可能で、例えば特定のキーワードが含まれるメールが来た場合のみ通知を行うなどの条件付きのワークフローを作成できます。
ビジネスにおける応用例
- マーケティング自動化: リードがフォームに記入した情報を基に自動的にメールを送信し、さらにCRMにリード情報を登録する。
- 顧客サポートの効率化: サポートチケットが作成されたときに自動で関連部門に通知し、必要に応じてフォローアップをスケジュールする。
- ITオペレーションの自動化: サーバーのダウンタイムや異常が検出された際に、関連するチームにリアルタイムでアラートを送信し、事前に定義されたトラブルシューティングプロセスを開始します。
AssemblyAIとは?
AssemblyAIは、最先端の技術を使用して開発された音声認識APIサービスです。このサービスは、開発者がアプリケーションに簡単に音声認識機能を組み込めるように設計されており、高精度なテキスト変換を実現します。さまざまな言語や方言に対応し、リアルタイムまたはバッチ処理のどちらでも対応可能です。
主な特徴
- 高精度: 最新のディープラーニングモデルを活用し、業界トップレベルの認識精度を提供します。
- 多言語対応: 英語を始め、多数の言語に対応しており、グローバルなビジネスニーズに応えることが可能です。日本語にもしっかり対応しています。
- 柔軟性の高いAPI: REST APIはシンプルで直感的な設計で、組み込みやすく、さまざまなプラットフォームとの互換性を保持します。
- リアルタイム処理: リアルタイム音声ストリーミングに対応し、即座にテキスト変換を行うことができます。
料金プラン
AssemblyAIの料金プランは、大きくは無料プラン、従量課金プランの2つのオプションが用意されています。具体的なプランは以下の通りです。無料プランでも100時間の音声をテキスト変換できるので試しに利用するにも十分です。
- 無料プラン: 開発者が試用するために無料で利用でき、最大100時間の音声をテキストに変換できます。スピーチ認識やスピーカーの識別、カスタムスペル、プロファニティフィルタリングなどが含まれます。
- 従量課金プラン: スピーチ認識の基本料金は$0.12からとなっており、リアルタイムのテキスト変換や、より高度なオーディオインテリジェンス機能が利用可能です。このプランでは、ファイルの同時処理が200件、ストリームが100件から可能です。
Nano, Baseと2つのモデルがあり、Nanoは$0.12/h、Baseは$0.37/hの金額となっています。ちなみにOpenAIのWhisperは$0.36/hなのでBaseがほぼ同額になります。 - カスタムプラン: 大規模な用途に対応し、ボリュームディスカウントや専任のサポートを提供します。EUデータレジデンス基準にも対応しており、企業向けにカスタマイズが可能です。

適用例
- 顧客サービスの自動化: 電話やビデオ通話での顧客とのやり取りをリアルタイムで文字に変換し、サポートの質と効率を向上させます。
- 会議の記録: 会議や講演をリアルタイムで文字起こしし、後で内容を確認するための文書を即座に生成します。
- メディア内容の字幕生成: 映像コンテンツにリアルタイムで字幕を付けることで、アクセシビリティを高めます。
具体的な文字起こし手順
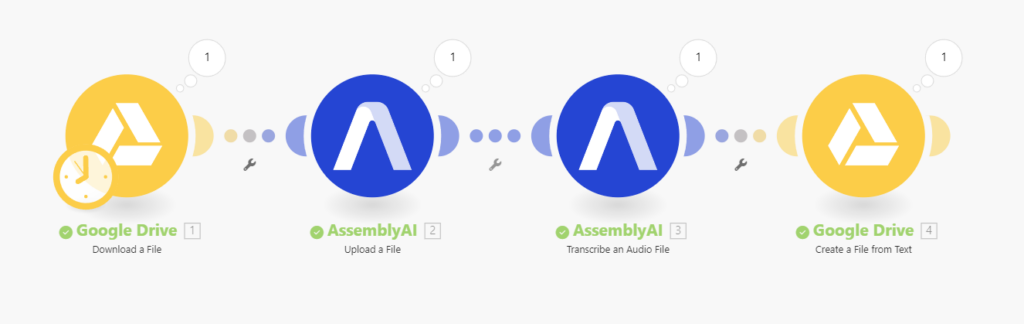
ゴールイメージ
最終的なゴールイメージはこんな感じです。今回はGoogle Driveにアップロードした音声ファイルをAsseemblyAIで文字起こしし、それをGoogle Driveにdocs形式で保存して終了です。
Make.comではChatGPTにも接続できるので文字起こしをした後に要約したり、その結果をメールで送信したりもすぐできます。
Youtubeの動画でも見れます。
- Google DriveへのアップロードとMake.comの設定
- 文字起こししたい音声ファイル(wav, mp3など)をGoogle Driveにアップロードします。
- Make.comでGoogle Driveとの連携を設定し、アップロードした音声ファイルをダウンロードできるようにします。
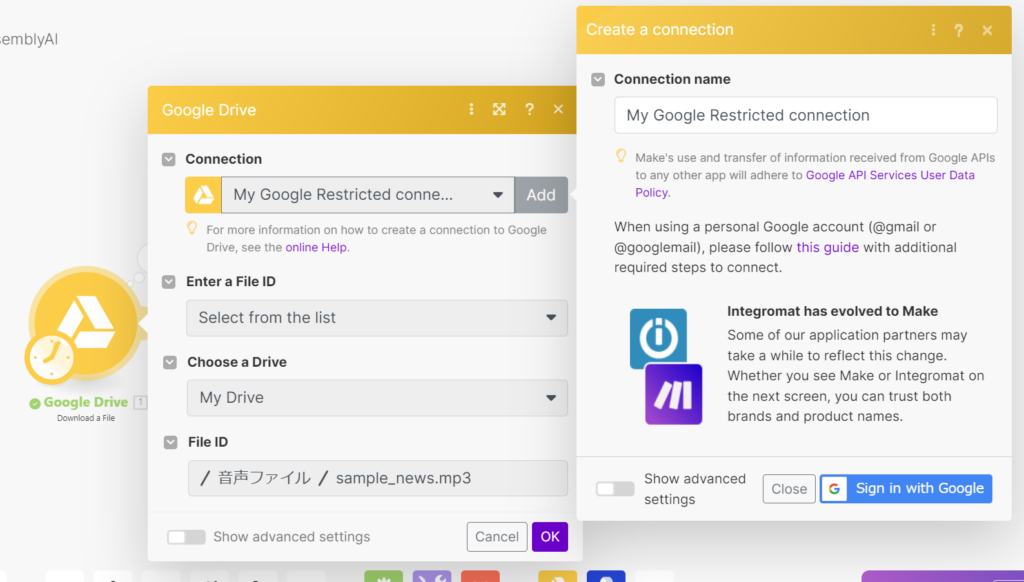
- Google DriveへはGoogle loginで接続できます。おそらく、最初は接続できないかもしれませんがその時はGoogle APIsが使えるようにガイドのリンク(this guideと表示)にアクセスして接続する手順に従ってGoogleアカウントの設定を実施してください。
Makeのページにやり方の手順が書かれています。 - Choose a Drive、File IDはEnter a File IDを”Select from the list”に設定すれば既存のディレクトリとファイルを選択形式で選べます。

- AssemblyAIへの連携とファイルのアップロード
- Make.comからAssemblyAIサービスへ接続し、ダウンロードした音声ファイルをAssemblyAIにアップロードします。
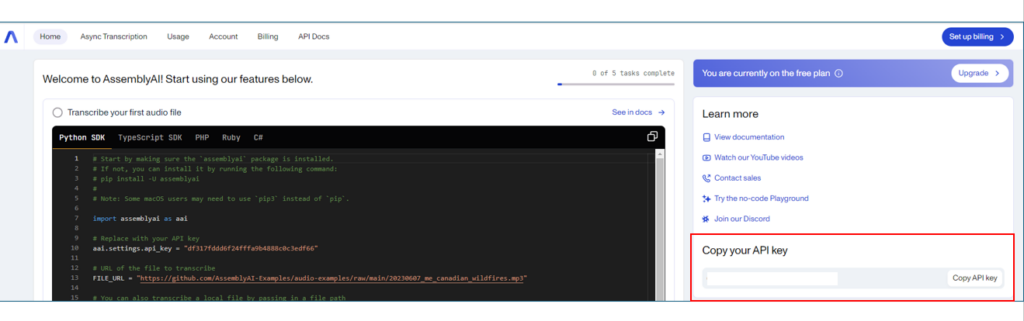
- AssemblyAIに接続するためのAPIキーはAssemlyAIにログインするとログインページのトップに表示されます。
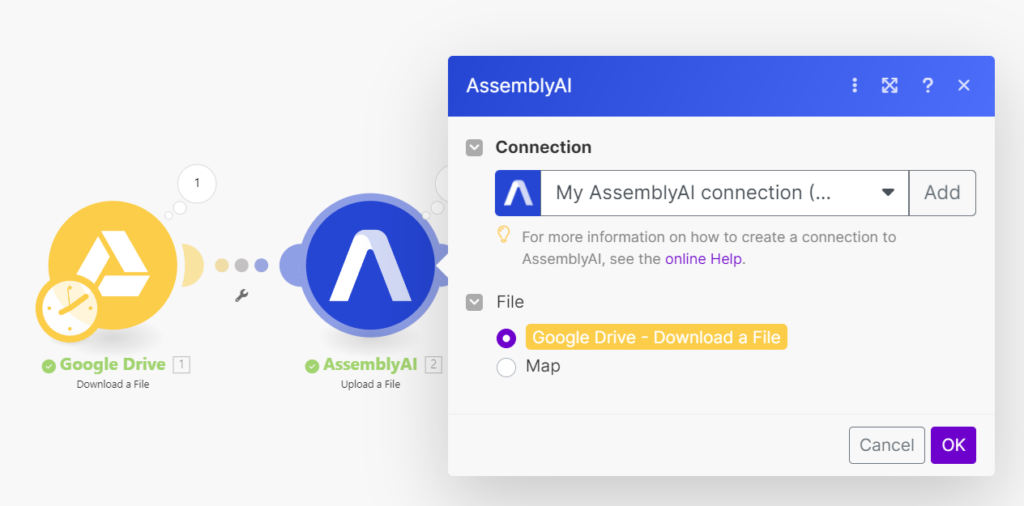
- AssemblyAIのモジュールは”Upload a File”を選び、ファイルのアップロードは以下の画像のようにGoogle Drive Download a Fileを設定してください。
- AssemblyAIでの音声認識実行
- アップロードした音声ファイルに対して音声認識を実行します。認識結果は文字データとして出力されます。
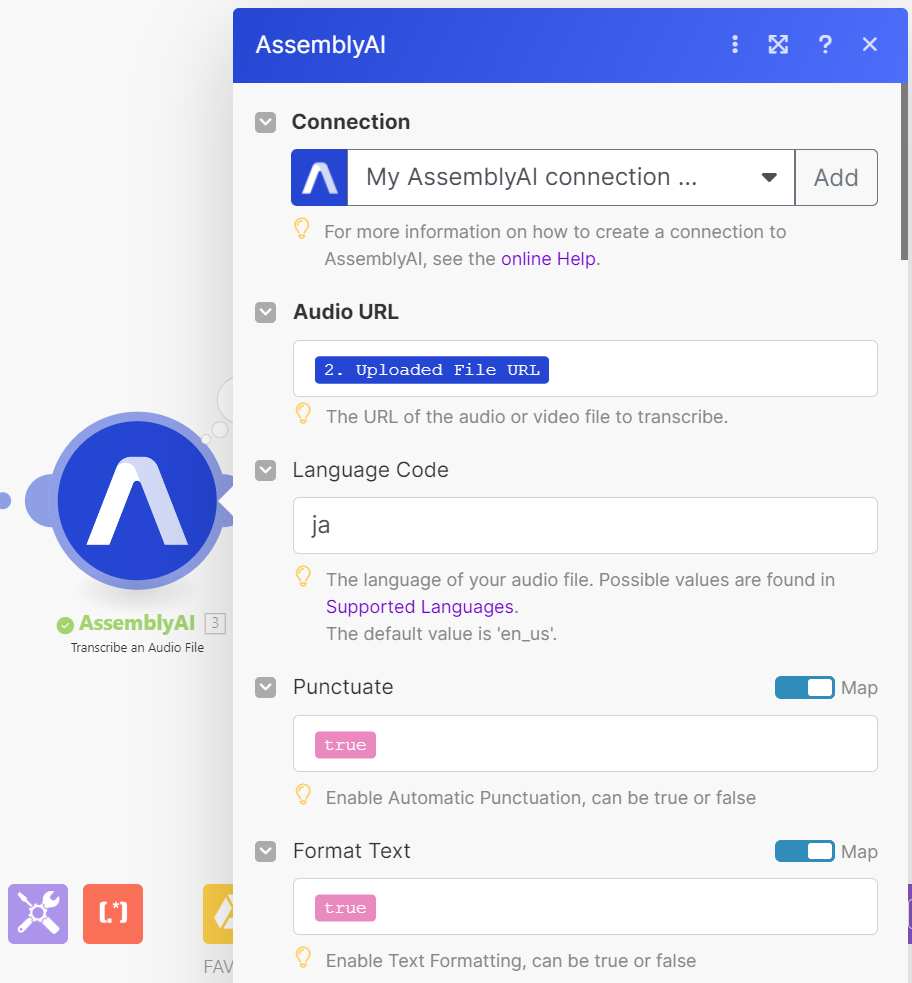
- AssemblyAIのモジュールはTranscribe an Audio Fileを選んでください。
- 設定は以下の絵のようにAudio URLでアップロードしたファイルのURLを選択。Language Codeは日本語ならjaを選んでください。(AssemblyAIのページに言語コードは記載されています)
- 他の設定はそのままでも動きますが、句読点を付ける場合はPunctuateの設定を行います。Speech ModelもNano、Bestの選択もこの画面から可能です。
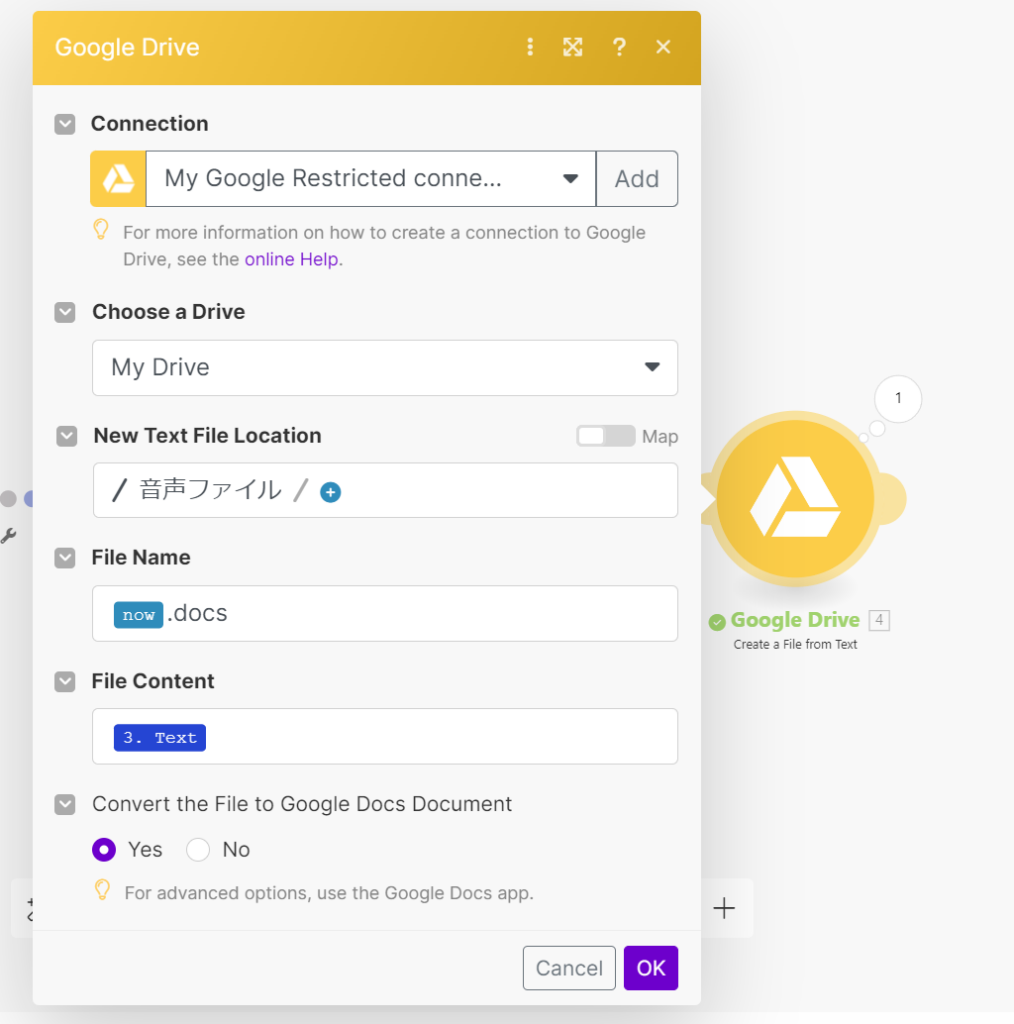
- 文字起こしデータのGoogle Driveへの保存
- 認識した文字データをMake.comを介してGoogle Driveに保存します。
- 好きなディレクトリを選択し、File ContentにAssemblyAIが文字起こししたTextを選べば完了です。
簡単、10分もあれば文字起こしが作れてしまいます!
文字起こしの利用シーン
- 会議録の自動文字起こし
- ミーティングの議事録作成に活用できます。出席者の発言内容をリアルタイムでテキスト化できます。
- 動画の字幕付け
- テレビ番組や動画配信コンテンツの字幕作成に役立ちます。音声から高精度の文字起こしを自動化できます。
- 音声データのデジタル化
- 録音されたインタビューや講演会の内容をテキストデータとして保存・活用できます。
まとめ
Make.comとAssemblyAIの連携により、プログラミングなしで音声認識の仕組みを構築し、様々なシーンで活用できる自動文字起こしシステムを簡単に実現できます。音声データの活用にお困りの方は、ぜひお試しください。
Make.comの使い方がわからない、社内のDX化を進めたい、個人で使えるAIツール、DXツールなどを相談したいという時はご相談ください。